Computing the matrix exponential in arbitrary precision
Edmond Laguerre was the first to discuss, en passant in a paragraph of a long letter to Hermite, the exponential of a matrix. In fact, the French mathematician confined himself to defining 
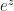
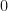
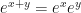
Despite the fact that the exponential is an entire function, Taylor and Padé approximants converge only locally, and may require an approximant of exceedingly high order for matrices of large norm. Therefore, scaling the input is often necessary, in order to ensure fast and accurate computations. This can be effectively achieved by means of a technique called scaling and squaring, first proposed in 1967 by Lawson, who noticed that by exploiting the identity 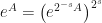


The choice of
These techniques, however, do not readily extend to arbitrary precision environments, where the working precision at which the computation will be performed is known only at runtime. In the EPrint An arbitrary precision scaling and squaring algorithm for the matrix exponential, Nick Higham and I show how the scaling and squaring method can be adapted to the computation of the matrix exponential in precisions higher than double.
The algorithm we propose combines a new analysis of the forward truncation error of Padé approximants to the exponential with an improved strategy for selecting the parameters required to perform the scaling and squaring step. We evaluate at runtime a bound that arises naturally from our analysis in order to check whether a certain choice of those parameters will deliver an accurate evaluation of the approximant or not. Moreover, we discuss how this technique can be implemented efficiently for truncated Taylor series and diagonal Padé approximants.

- Top left: forward error of several algorithms on a test set of non-Hermitian matrices. Top right: corresponding performance profile. Bottom: legend for the other two plots. Variants of our algorithm are in the top row, existing implementations for computing the matrix exponential in arbitrary precision are in the bottom row.
We evaluate experimentally several variants of the proposed algorithm in a wide range of precisions, and find that they all behave in a forward stable fashion. In particular, the most accurate of our implementations outperforms existing algorithms for computing the matrix exponential in high precision.
